
Введение
Несомненно, самый упускаемый из виду аспект поисковой системы — это наполняемость и индексируемость сайта: тайное искусство подстраивания ваших веб-страниц под Googlebot.
Если вы сможете сделать это правильно, то ваши результаты улучшатся. Каждое небольшое изменение может привести к большим успехам в поисковой выдаче. Однако если все сделать неправильно, то вы будете неделями ждать сканирования от Googlebot.
Меня часто спрашивают, как заставить Googlebot быстро индексировать сайт в целом и отдельные страницы. Многие сайты даже борются за быструю индексацию.
Что ж, сегодня ваш счастливый день — потому что после прочтения этой статьи все подобные вопросы отпадут.
В ней я расскажу вам о четырех основных аспектах сканирования сайта, чтобы вы могли принять действенные меры по улучшению позиций в поисковой выдаче.
Столп № 1: Быстрая индексация сайта: Блокировка страниц
Веб-краулеры — важнейшие инструменты современного интернета. Они работают точно, и Google выделяет «бюджет на сканирование» для каждого краулера. Чтобы убедиться, что Google просматривает именно те страницы, которые вам нужны, не тратьте этот бюджет на неработающие страницы.
Именно здесь и приходит на помощь запрет индексации страниц для краулеров.
Когда дело доходит до запрета индексации, у вас есть множество вариантов, и только от вас зависит, какие из них использовать. Я дам вам инструменты, но вам придется провести аудит своего сайта перед этим.
Robots.txt
Поисковые системы используют продвинутые алгоритмы для сортировки миллионов страниц, чтобы мы могли легко найти то, что нам надо.
Существует множество поисковых систем, которые доказали свою перспективность. Простая техника которую я люблю использовать, — это запрет индексации страниц с помощью robots.txt.
Изначально эта директива была разработана в результате случайной DDOS-атаки на сайт с помощью краулера Google; она получила неофициальное признание со стороны компании.
Хотя стандарта ISO для robots.txt не существует, у Googlebot есть свои директивы. Но вкратце можно сказать, что вы можете просто создать файл .txt с именем robots и дать боту указания о том, как себя вести. Вам нужно будет структурировать его так, чтобы каждый поисковый бот знал, какие правила поисковой системы применяются к нему самому.
Для примера:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://site.com/sitemap.xml
Это короткий и понятный файл robots.txt, который вы, скорее всего, найдете на просторах интернета. Здесь он разбит на части:
- User-Agent — здесь указывается, какие роботы должны придерживаться этих правил. В то время как хорошие боты обычно следуют этим директивам, плохие боты их нарушают.
- Disallow — запрещает поисковым роботам сканировать папку /wp-admin/, где хранится множество важных документов для WordPress.
- Allow — говорит ботам, что, несмотря на то, что папка под запретом /wp-admin/ бота разрешено просканировать один фал. Файл admin-ajax.php очень важен, поэтому вы должны держать его открытым для поисковых систем.
- Sitemap — одним из наиболее часто встречающихся директив это директива sitemap. Она помогает Googlebot найти вашу XML-карту сайта и быстренько проиндексировать все имеющиеся там ссылки.
Если вы используете Shopify, то вам знакомы трудности цифрового маркетинга, связанные с отсутствием контроля над файлом robots.txt. Вот как, выглядит хорошая структура сайта:
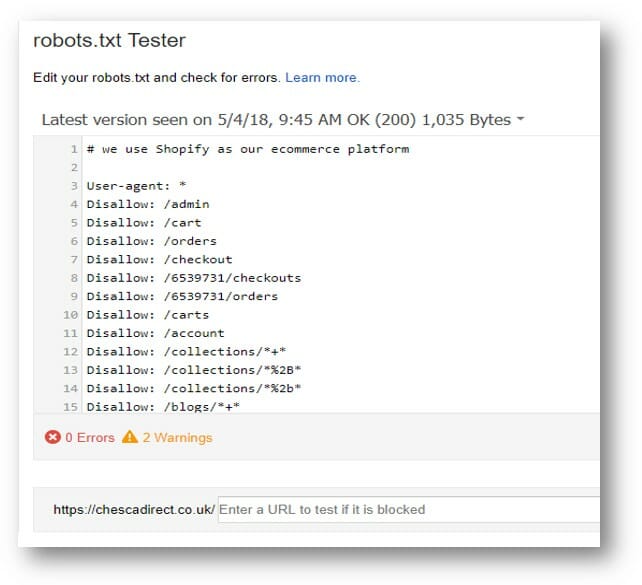
Быстрая индексация сайта: Meta Robots
Теги meta robots представляют собой HTML-код, который можно использовать для указаний поисковой системы.
По умолчанию все контентные страницы вашего сайта будут настроены на индексирование. Эта настройка гарантирует, что ваша веб-страница будет видна поисковым системам.
Добавление этого тега не поможет вашей странице попасть в поисковую выдачу и проиндексироваться, поскольку он установлен по умолчанию. Однако если вы хотите остановить сканирование и индексирование неработающей страницы на вашем сайте, то вам нужно указать данный тег.
<meta name="robots" content="noindex,follow">
<meta name="robots" content="noindex,nofollow">.Хотя теги follow links технически отличаются с точки зрения директив для роботов, по мнению Google, они функционируют одинаково.
Раньше вы указывали параметр noindex, чтобы запретить просмотр страницы роботами. Кроме того, можно было указать, сканировать ли на странице ссылки, ведущие на нее.
Недавно Google сделал заявление о том, что неиндексированная неработающая страница в конечном итоге рассматривается как 404 ошибку, а ссылки на нее — как nofollow. Поэтому с технической точки зрения нет никакой разницы между указанием ссылок follow и nofollow.
Однако если вы не доверяете всему, что утверждает Джон Мюллер, вы можете использовать ссылки noindex и follow, чтобы указать, как вы хотите, чтобы по вашей страницу индексировали.
Yoast взял это на вооружение, поэтому в последних версиях плагина Yoast SEO вы заметите, что опция noindex для пагинации была удалена.
Это связано с тем, что если Googlebot воспринимает тег noindex как 404 ошибку, то делать это для всей пагинации — плохая идея. Я бы придерживался осторожности и использовал его только для страниц с битыми ссылками и серверными редиректами.
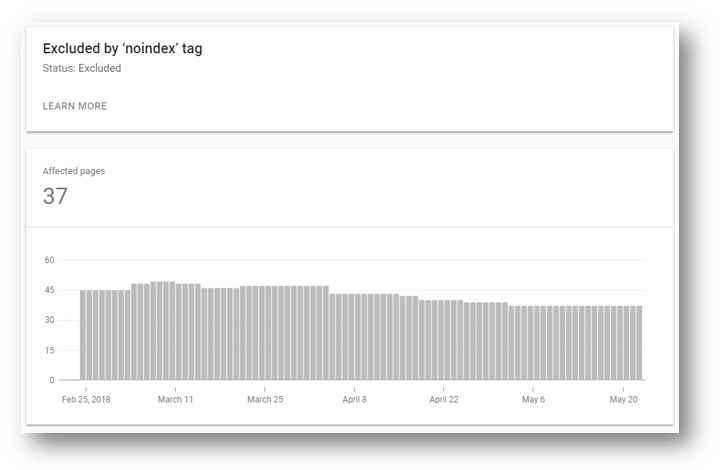
Теги X-Robots
Есть ещё один способ которые люди не так часто используют это X-Robots. X-Robots это очень мощный способ, но не многие понимают, почему они такие мощные.
С помощью директив robots.txt и meta robots — робот сам решает, выполнять установленные команды или нет. Это касается и Googlebot, он все равно может просканировать все страницы, на всякий случай.
Используя данный заголовок сервера, вы можете сказать роботам, чтобы они не сканировали весь ваш сайт с сервера. Это означает, что у них не будет выбора в этом вопросе, им просто будет отказано в доступе к сайту.
Это можно сделать либо с помощью PHP, либо с помощью директив Apache, поскольку и те, и другие обрабатываются на стороне сервера. При этом .htaccess является предпочтительным методом для блокировки определенных типов файлов, а PHP — для определенных страниц.
Код PHP
Вот пример кода, который вы будете использовать для блокировки неработающей страницы с помощью PHP. Он прост и будет обрабатываться на стороне сервера.
header(«X-Robots-Tag: noindex», true);
Директива Apache
Вот пример кода, который можно использовать для блокировки файлов .doc и .pdf в поисковой выдаче без необходимости запрещать каждый файл PDF в robots.txt.
<FilesMatch “.(doc|pdf)$”>
Header set X-Robots-Tag “noindex, noarchive, nosnippet”
</FilesMatch>
Столп № 2: Понимание поведения кроулеров
Быстрая индексация сайта: Бюджет для сканирования
Когда речь заходит о бюджете для сканирования, это то, что существует только в теории, но не на практике. Это означает, что нет способа искусственно раздуть бюджет для сканирования.
Для тех, кто не знаком, это количество времени, которое поисковой паук Google потратит на ваш сайт. Маркетплейсы с тысячами товаров будут просматриваться более интенсивно, чем микросайты. Однако на микросайте основные страницы будут просматриваться чаще.
Если у вас возникают проблемы с тем, чтобы поисковая система просматривала чаще важные страницы, вероятно, причина в этом. Либо они были заблокированы, либо имеют низкую ценность.
Вместо того чтобы пытаться принудительно заставить робота сканировать ваши страницы, вам, следует устранить корень проблемы.
Тем не менее, вы можете проверить выставлена ли средняя скорость сканирования вашего сайта в Google Search Console > Статистика сканирования (Crawl Stats)

Глубина сканирования (Depth First Crawling)
Один из способов, с помощью которого боты поисковых систем могут действовать как краулеры на вашей веб-странице, — это принцип depth-first. Это заставляет бота Google сканировать как можно глубже, прежде чем возвращаться вверх по иерархии.
Это эффективный способ выполнения ботами своей работы, если вы хотите проиндексировать внутренние ссылки с релевантным контентом за максимально короткое время.
Эффективная структура внутренних ссылок помогает посетителям сайта легко ориентироваться, а также помогает поисковым системам понять релевантный контент сайта. Структура внутренних ссылок также способствует повышению авторитетности страниц, что может привести и к повышению позиций.
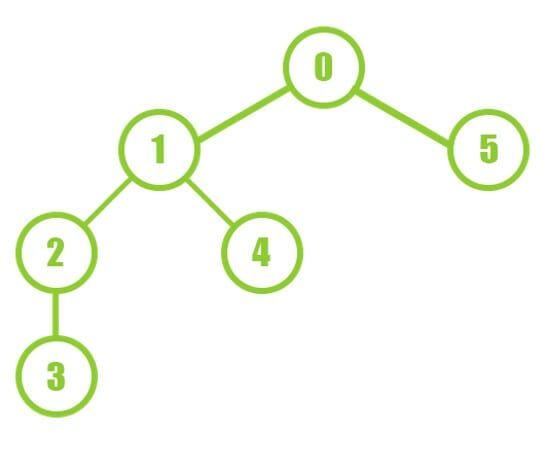
Сканирование в ширину (Breadth First Crawling)
Это противоположность сканированию в глубину, cначала краулер сканирует каждую страницу уровня 1, а затем каждую страницу уровня 2 и т.д.
Преимущество этого типа веб-краулера в том, что он, скорее всего, обнаружит больше уникальных URL-адресов за более короткий период времени. Это связано с тем, что он путешествует по нескольким категориям вашего сайта, не обращая внимания на старые или удаленные URL-адреса.
Таким образом, вместо того чтобы копать вглубь кроличьей норы, этот метод направлен на то, чтобы найти все кроличьи норы.
Однако, несмотря на то, что этот метод хорош для сохранения структуры сайта, он может быть медленным, если страницы сайта категории долго загружаются и отвечают на запросы.
Эффективность сканирования (Efficiency Crawling)
Существует множество различных способов сканирования, но наиболее популярными являются два вышеперечисленных, а третий — «Эффективное скаирование (Efficiency Crawling)». В этом случае краулер Google не смотрит в первую очередь на ширину или глубину, а основывается на времени отклика.
Это означает, что если у веб-краулера есть час на сканирование, они выберут все страницы сайта с низким временем отклика. Таким образом, за более короткий промежуток времени будет пройдено большее количество страниц. Отсюда и появился термин «краулинговый бюджет».
По сути, вы пытаетесь сделать так, чтобы ваш сайт отвечал как можно быстрее. Это делается для того, чтобы за отведенный промежуток времени можно было просмотреть больше страниц сайта.
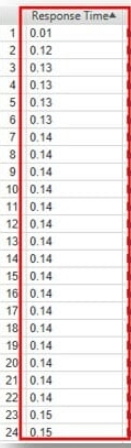
Скорость сервера
Многие люди не понимают, что Интернет связан с физическим миром. Миллионы устройств, подключенных по всему миру, обмениваются файлами и передают их друг другу.
Однако ваш сайт размещается где-то на сервере. Чтобы Google и ваши пользователи могли открыть вашу веб-страницу, необходимо соединение с вашим сервером.
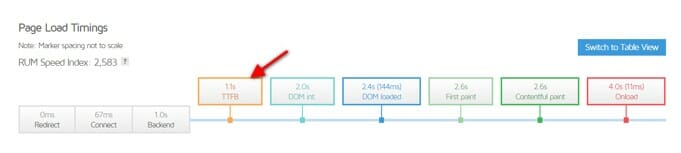
Чем быстрее ваш сервер, тем меньше времени Googlebot придется ждать важные файлы. Если мы рассмотрим вышеприведенный раздел об эффективности сканирования, то станет ясно, что анализатор лог-файлов очень важен.
Когда речь идет о ботах поисковых систем, стоит приобрести качественный хостинг, расположенный как можно ближе к вашей целевой аудитории. Это позволит снизить задержку и время ожидания каждого файла. Однако если вы хотите распространять информацию на международном уровне, вам может понадобиться CDN.
Сети распространения контента (CDN)
Поскольку поисковая система Googlebot осуществляет поиск с серверов Google, они могут находиться физически очень далеко от сервера вашего сайта. Это означает, что Google может воспринимать ваш сайт как медленный, несмотря на то, что пользователи воспринимают его как быструю веб-страницу.
Одним из способов решения этой проблемы является настройка сети распространения контента соответствующей страницы.
Существует множество вариантов, но все очень просто. Вы платите за то, чтобы веб-краулеры распространяли содержимое вашей страницы по сети Интернет.
Так оно и есть, но многие люди спрашивают, зачем нужны веб-краулеры.
Если веб-краулеры распространяют содержимое страницы вашего сайта по сети Интернет, физическое расстояние между конечным пользователем и файлами может быть сокращено. Именно это содержимое люди видят на странице результатов поиска.
В конечном итоге это означает, что уменьшается задержка и ускоряется загрузка всех страниц результатов поиска.

Столп № 3: Множество ненужных страниц
После того как вы усвоили все вышесказанное и как ведут себя краулеры, следующий вопрос должен быть таким: как заставить поисковую систему Google просканировать нужные мне страницы сайта.
Ниже вы найдете несколько советов о том, как свести концы с концами на вашем сайте, создать воронку и повысить эффективность работы краулеров.
Битые ссылки
Битые ссылки могут быть серьезной проблемой, когда речь идет о юзабилити веб-страниц и поисковой оптимизации. Они могут влиять на то, что отображается на странице результатов поиска.
В начале каждой кампании необходимо проработать все неработающие внутренние ссылки. Для этого мы ищем все неработающие серверные редиректы, которые обнаруживаются в AHREFS.
Это не только поможет направить ссылочный вес на ваш сайт, но и покажет, какие именно битые серверные редиректы были обнаружены. Это поможет краулерам удалить из индекса все непреднамеренные 404 ошибки, которые все еще находятся в Интернете.
Если вы хотите быстро исправить ситуацию, вы можете экспортировать список неработающих серверных редиректов, а затем импортировать их все в ваш любимый плагин редиректа. Лично мы используем Redirection и Simple 301 Redirects для наших сайтов на WordPress.

Screaming Frog Broken Links
Как и в предыдущем случае, в Screaming Frog мы сначала экспортируем все 404 ошибки сервера, а затем добавляем редиректы. Это позволит перенести все ошибки на 301 редирект.
Следующий шаг по очистке сайта — усиление внутренних ссылок. Внутренние ссылки могут повысить рейтинг вашего сайта в поисковых системах.
Хотя 301-я редирект может передавать сигналы авторитетности и релевантности внутренних ссылок, но лучше, если ваш сервер не обрабатывает множество редиректов. Возьмите за привычку чистить свои ссылки и не забывайте оптимизировать анкоры!

Быстрая индексация сайта: Ошибки карулера в поисковой консоли
Еще одно место, где вы можете найти ошибки, — это Google Search Console. Это удобный способ увидеть ошибки, которые Googlebot уже обнаружил.
Затем сделайте, как описано выше, экспортируйте их все в csv и массово пропишите редирект. Это исправит почти все ваши 404 ошибки за пару дней. После этого Googlebot будет тратить больше времени на поиск релевантных страниц вашего сайта и меньше — на неработающие страницы.

Анализ журналов сервера
Анализатор логов — это ключ к мониторингу всей производительности ваших операций! С помощью анализатора логов можно легко увидеть визуально даже самые сложные данные, чтобы получить полезные сведения.
Хотя все вышеперечисленные инструменты полезны, они не являются лучшим способом проверки. Просматривая журналы сервера через Screaming Frog Log File Analyzer, вы сможете найти все ошибки, которые были отправлены вашим сервером.
Screaming Frog отфильтровывает обычных пользователей и фокусируется в основном на ботах поисковых систем. Казалось бы, это дает те же результаты, что и выше, но обычно они более подробны и содержат релевантные ключевые слова.
В него входят не только все боты Google, но и других поисковых систем, таких как Яндекс и Bing.
Внутренние ссылки
Внутренние ссылки могут существенно повлиять на производительность вашего сайта.
Один из способов повысить скорость сканирование конкретной страницы — усилить её внутренними ссылками. Это простой способ, но он может в разы улучшить ваши результаты.
С помощью анализатора логов Screaming File, о котором говорилось выше, вы можете увидеть, какие страницы получают больше всего обращений от Googlebot. Если страница регулярно посещается в течение месяца, велика вероятность, что вы нашли кандидата на внутреннюю перелинковку.
На этой странице могут быть добавлены ссылки на другие основные посты, и это поможет Googlebot попасть в нужные области вашего сайта.
Столп № 4: Принудительное сканирование
Если Googlebot сканирует сайт и не находит ваши основные страницы, это, как правило, большая проблема. Или если ваш сайт слишком велик и бот не может проиндексировать его — это плохой знак.
Поисковые системы реагируют негативно на такие факторы и это может привести к внезапному падению позиций вашего сайта. Однако алгоритм поисковых систем разработан таким образом, чтобы вознаграждать сайты с акутальным, релевантным и актуальным контентом, а принудительное сканирование может привести к появлению в индексе устаревшего или нерелевантного контента.
К счастью, аудит сайта может помочь вам заставить бота активнее сканировать ваш сайт. Однако сначала следует сказать несколько слов предостережения по поводу этого подхода:
Если веб-краулеры регулярно не посещают ваш сайт, то на это обычно есть веская причина. Наиболее вероятная причина заключается в том, что Google не считает ваш сайт ценным.
Еще одна веская причина плохой посещаемости и индексируемости сайта — его раздутость. Если вы боретесь за то, чтобы миллионы страниц были проиндексированы, ваша проблема в полезности контента на миллионах страниц, а не в том, что они не проиндексированы.
За всё время работы мы видели десятки примеры сайтов, которые были избавлены от санкций Panda, а проблема была в наполняемости и индексируемости. Если бы мы сначала исправили проблему с наполняемостью и индексируемостью сайта, не устранив не нужный контент, мы бы в итоге получили опять получили санкции.
Важно устранить все проблемы вашего сайта, если вы хотите, чтобы он долгое время занимал высокие позиции в выдаче.
Быстрая индексация сайта: Sitemap.xml
Это кажется очевидным, но поскольку Google использует XML Sitemaps в качестве первого касания — сделайте sitemap.xml и отправьте его ему.
Просто возьмите все URL-адреса, которые вы хотите проиндексировать, затем запустите Screaming Frog в режиме списка, выбрав в меню пункт «Список (List)» для отправки sitemap:

Затем вы можете загрузить URL из следующих вариантов в выпадающем списке:
- Из файла
- Ввести вручную
- Вставить
- Загрузить файл Sitemap
- Загрузить Sitemap Index

После того как вы улучшите наполняемость и индексируемость своего сайта, обеспечив индексацию всех нужных вам URL-адресов, вы можете просто воспользоваться функцией отправки Sitemap.

Поместите его в корневой каталог, а затем загрузите в поисковую систему Google, чтобы быстро удалить все дубликаты страниц или страницы, не отвечающие требованиям к качественному контенту.

Индексирование по запросу (Fetch and Request Indexing)
Если у вас небольшое количество страниц, которые нужно проиндексировать, то использование инструмента Индексирование по запросу (Fetch and Request Indexing) будет очень полезным.
Он отлично работает в сочетании с отправкой карты сайта для эффективного повторного индексирования вашего сайта за короткий промежуток времени. Здесь особо нечего сказать, кроме того, что вы можете найти его в консоли поиска Google > Сканировать (Crawl) > Просмотреть как Google (Fetch as Google).

Построение ссылок
Логично, если вы пытаетесь проиндексировать страницу в поиске и повысить посещаемость сайта, то размещение прямых ссылок на неё поможет вам в этом.
Обычно 1 — 2 ссылки в карте сайте (на неё) помогут решить проблему с индексацией. Это произойдёт примерно так, Google просматривает разные страницы, а затем обнаруживает ссылку на вашу. Это не оставит Googlebot другого выбора, кроме как просканировать эту страницу.
Использование низкокачественных ссылок сделанных специально для индексации также может сработать, но я бы рекомендовал вам стремиться к высококачественным ссылкам. Это в конечном итоге повысит вероятность того, что ваш сайт будет просканирован, так как качественный контент также увеличивает посещаемость сайта.

Быстрая индексация сайта: Инструменты для индексирования
К тому времени, когда вы перейдете к использованию сервисы для индексации, вы, вероятно, уже использовали все идеи какие у вас есть…
Аудит сайта может помочь вам определить, насколько качественны ваши страницы. Если страницы вашего сайта проиндексированы, находятся в карте сайта, ищутся в поиске у них есть посещаемость, имеют несколько внешних прямых ссылок, но до сих пор не проиндексированы, вы можете попробовать другой трюк.
Многие используют для индексации сервисы для аудита сайта — ведь во время аудита сайта на самом сайте остаётся ссылка которую может проиндексировать Гугл и затем посетить ваш сайт, но в большинстве случаев это пустая трата времени. Результаты часто ненадежны, и если вы сделали все остальное правильно, то у вас не должно быть проблем.
Тем не менее, вы можете использовать сервисы для аудита сайта, такие как Lightspeed Indexer, чтобы попытаться повысить сканируемость вашего сайта. Существует множество других инструментов, и все они имеют свои уникальные преимущества.
Большинство из этих инструментов работают путем отправки пингов поисковым системам, подобно Pingomatic.

Подведение итогов для быстрой индексации сайта
Когда дело доходит до поисковых машин индексирующих ваш сайт, существует масса различных способов решить любую проблему, с которой вы столкнулись. Фокус долгосрочного успеха заключается в том, чтобы определить, какой подход лучше подходит именно вам, проведя веб-аудит.
Мой совет каждому SEOшнику таков:
Приложите усилия, чтобы понять основные принципы построения Интернета.
Без этого фундамента остальные возможности поисковых систем превращаются в серию магических трюков. Однако если вы это поймёте, то все остальное, что касается возможностей поисковой системы, станет для вас открытой книгой.
Постарайтесь запомнить, что алгоритм в значительной степени математический. Поэтому даже, если ваш контент может быть сразу же с теплотой принят новой аудиторией, вы всё равно должно проставлять обратные ссылки для быстрой индексации сайта.
Учитывая все вышесказанное, удачи вам в установлении взаимовыгодных отношений с поисковыми краулерами, и если у вас все еще есть проблемы, вы знаете, где нас найти!